01-Class_Logs
0301-0302 Transformer🌟🌟🌟
- 0301:input序列长度大于embedding时候的seq_len时, input的输入序列会按照seq_len进行切割拼接到batch上吗? (老师讲了encoder时候input不足seq_len时候使用mask然后想问的另一个问题)
- 0302:
K-V cache时候当预测下一个时间步的时候与之前的做Attention的时候, 中途会取出cache里的K—V吗还是只取出里面的K还是只在最后一个结束后才整体取一次 (我想问的也就是在一个batch或者一个seq的访存情况, 每一个时间步都需要访问cache一次吗) - 是直接使用缓存的填充矩阵还是需要拿出缓存数据(读还是取)
0308-0309——PyTorch
提及: 混合精度训练
1.1 Tensor 中数据的连续性
reshape, transpose, view, T(转置), permute
transpose会让raw data不变(共用), mata data的stride和shape等属性就变了 is_contiguous()不连续, 但reshape和permute这些是不会变的,因为他们会发生data copy, contiguous()会发生copy raw data数据
view和reshape的区别
view更加安全, 不会重新拷贝数据, 但数据不连续不能使用view,也就是stride不协调, reshape不会错误, 会重新拷贝数据, 数据也连续
permute和transpose会让stride属性改变, 从而发生数据不连续, 通常使用后要加一个contiguous()让数据连续
1.2 pytorch autograd
……………………
叶子结点+requests_grad=True才有最终的grad, 非叶子结点中途可能会计算grad, 但用了就会丢弃(requests_grad=True的)
梯度累加也有可能, 多个step的梯度累加, 隐式增加batch
若没进行xxx.grad.zero_()或者xxx.grad = None, 则会进行accumulate()累加grad, 这两种方法有一点区别, zero__()会置零,会占用显存, 但=None的话会释放显存, 两者各有好坏
1.3 inplace-op

叶子结点的Tensor变量不能进行in-place操作, 因为要更新梯度的时候要用叶子结点
no_grad()底层是基于set_grad_enable(Flase)的
1.4 自动微分机制(auto grad) 重点:
- pytorch中 正向forward 对我们用户是可见的,但是backward对我们用户是不可见的;
- 一般情况下,每一个正向的函数,都对应一个反向的函数(grad_fn--> Tensor中);
- tensor:requires_grad = True
- tensor: grad --> tensor 中存储grad的地方;
- tensor: grad_fn --> 存储我们反向函数的地方
- tesnor: is_leaf --> 这个tensor 是不是 叶子节点;
- net::all weight --> 都是leaf
- 叶子节点的梯度会自动保存下来的(weight);
- 中间的 activation 的梯度会计算,但是不保留;
- pytorch 动态图 vs tensorflow 静态图;
- 我们不能改变一个非叶子节点的 requires_grad;
- 非叶子(一个函数的output)节点它的 requires_grad 自动推导的;
- 非叶子节点对应函数的inputs 中只要有一个 requires_grad = True, 那么这个非叶子节点的requires_grad = True;
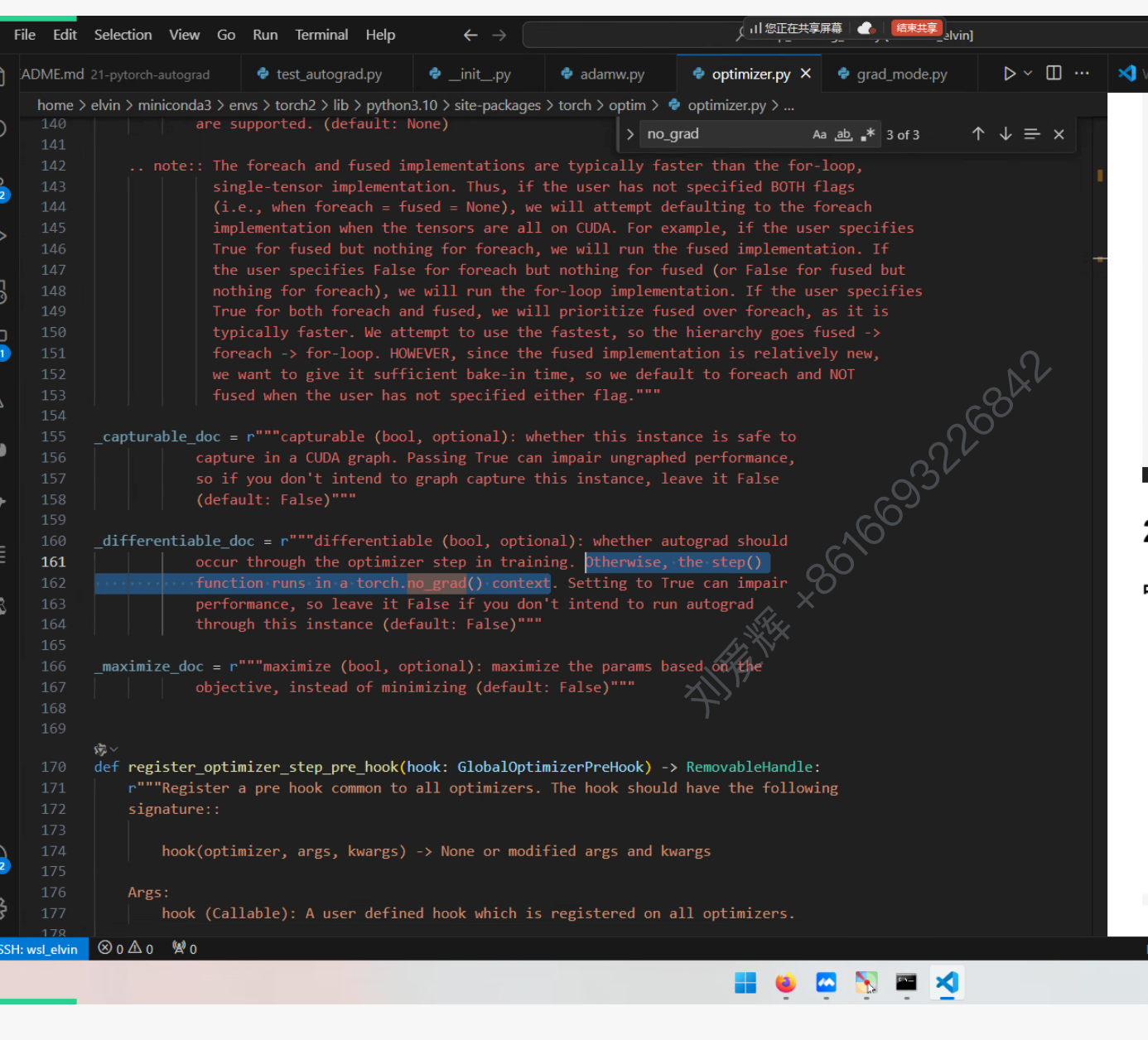
- torch.no_grad() 会使得里面的新的tensor requires_grad = False
- inplace的操作,非常大的风险:覆盖了原来的值,导致反向传播时计算不准确;
- 标量的梯度才能被隐式创建,隐式创建(.backward(1));
- 一般情况下,.backward(gradient)是有输入的: ;
2.1 torch.nn.Module
train模式和veal模式不会对grad的情况做修改,只是对训练和推理的对应的算子做不同的处理(等价处理)
常用算子dropout和BachNorm
xxx.cuda()的时候搬迁的是_parameters到cuda, 还有buffer也搬迁到cuda, 并没有将模型结构进行搬迁.
按照深度优先遍历sub module,将里面的_parameters和buffer到cuda, 数据类型转换也是一样的操作
c++底层实现了一个dispather分发机制,按照device属性分发, 对应device会调用对应的fn算子, 计算部分才执行
_parameters()送参数给优化器的时候将所有的parameters送到optim, 但数据共用, 同时更新
钩子函数(没太懂)
0315-0316(续PyTorch)
1.1 回顾
1.Tensor类和重要属性 2.autograd,动态图 3.Module以及属性和方法
training,_parameters,_buffers,_modules(hooks是主要用二次开发等情况)
子模块啥时候定义的呢?
_parameters,_buffers哪些有哪些没有
将module里的parameters传给optim,会通过调用parameters()进行
一系列方法具体情况
1.2 问题合集
- 在讲transformer的padding mask的时候想到,如果输入seq_len大于了定义的seq_len,会直接截断还是截断再拼接到下一个batch
- 在sequence mask的时候,忘了要问啥了
- 在normalization层的时候不是有两个学习的参数吗,这俩参数是一次forward训练一次还是单独有自己的训练?还有,这俩参数是咋更新的?
- dataset会迭代的将所有数据加载到内存吗,然后dataloader再一批次的提取吗
with torch.no_grad(): eval时候用,计算图不再进行,对require_grads=True的不进行梯度计算,显存占用量会减少,activation的就会丢弃
dataset会迭代的将所有数据加载到内存吗,然后dataloader再一批次一批次的提取吗?还是说dataloader准备拿一个batch,然后dataset根据batch_size迭代获取size条。
是后者,也就是I/O的时候,batch_size太小的话会增加I/O负担
2.1 torch.optim
参数传param的时候的传递和打包方式
self.param_groups
==self.state==:训练时候显存消耗的主要项(优化器的动量项有关) 他是一个dict,keys是tensor,values也是 模型
移动指数平均是啥忘了
def load_state_dict
2.2 learning rate 调整方案
Torch.optim.lr_scheduler
震荡类型的学习率调整是减少进入局部最优解的情况
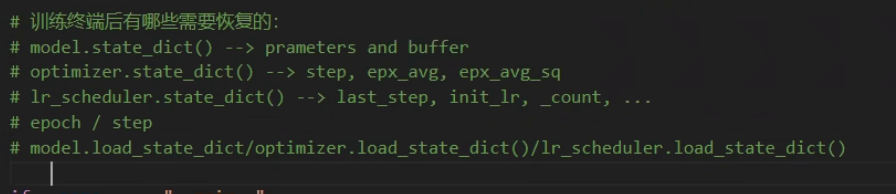
==状态字典==,三个地方见过,都类似,模型保存时候需要有
2.3 模型保存和加载
==动态图==
1.save state_dict的时候只有参数,save model的时候无法直接保存整个网络,但是他的材料(init)的那些会保存,模型加载的时候能通过,但runing time时候,forward并没有,必须导入或者自己实现,需要原来Net的签名(具体定义可以不一致,会放入_modules)
2.如果是自己写的算子,在init时候也放入_modules吗?
3.==onnx==模型保存必须输入对应的input,自己run一遍,是一个静态图
4.训练中的保存和加载(check point)==模型保存的几种参数类型==)
3.1 Dataset and Dataloader
只学习pytorch的,后续自己补hf的那些
4.1 NLP
GPT:自监督训练得到预训练模型(采用迁移学习)
Bert:完形填空
迁移学习:预训练+微调(微调的数据集就是专业领域的数据集)
4.2 Bert
1.两个任务:MLM和NSP
2.Embedding,词嵌入
词,句子(分段),位置 嵌入
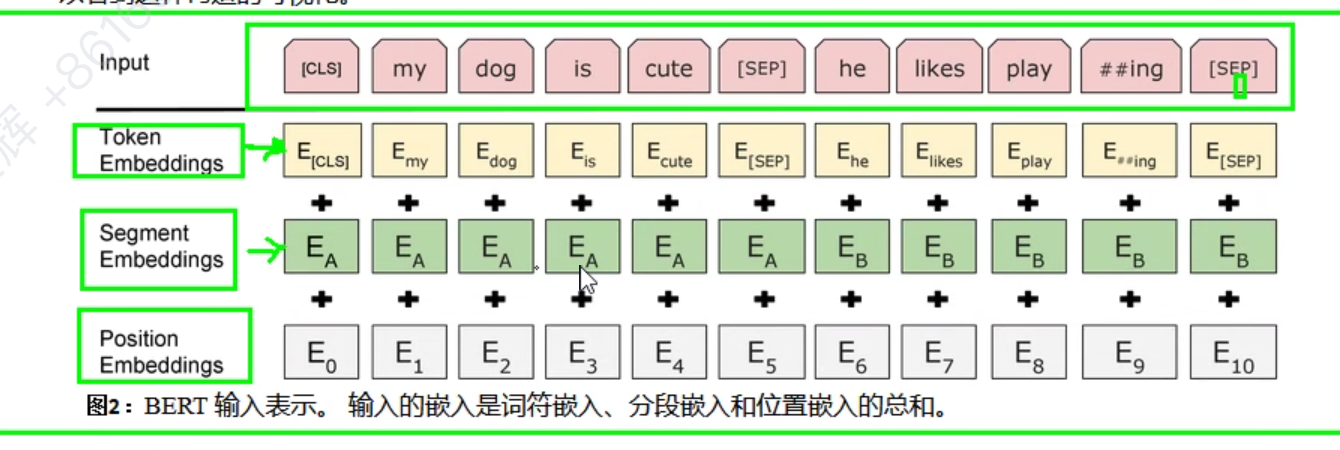
transformer的词嵌入式用三角位置嵌入
未讲知识:分词器tokenizer
0322
1.1 回顾
bert4torch的ner项目讲解和debug
2.1 T5讲解
2.2 position embedding🌟🌟🌟🌟🌟
绝对位置编码
- 三角函数式(Sinusoidal)
- 可学习(Learnable)
相对位置编码
- 是在Attention的时候才位置编码
- 只对q和k做位置编码,对value不做,value是结果或者说是token本身的特征信息
- T5的分桶思想
==旋转位置编码==(大模型使用的方法)
- 根据数学原理推导

- 想要得到的效果=>反推
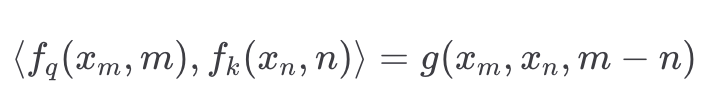

3.1 GPT
GPT-1 已经出现zero-shot迹象,层归一化还是之前的post-norm
GPT-2 零样本学习,即zero-shot,层归一化有点变化,改成per-Norm
相当于纯预训练

GPT-3 few-shot(给案例),发现模型规模可以提高能力,最后实现了无需微调到达一些较好的任务处理,架构基本和GPT-2一致,但加了一个新的‘交替的稠密和稀疏的’Attention,余弦衰减的学习率策略,batch-size从小变大,再加上0.1的权重衰减正则化
Few-shot, one-shot, zero-shot
• Few-Shot(FS): 模型在推理时给出K个任务示例作为上下文信息,同时提供任务的自然语言描述,但不允许模型进行权重更新。通常将K设置在10到100的范围内,以适应模型的上下文窗口。
• One-Shot(1S): 模型在推理时通过提供一个任务示例作为上下文信息,同时还有任务的自然语言描述。这种方式最接近于人类在解决某些任务时所使用的方式。
• Zero-Shot(0S): 不提供任何上下文信息,模型只给出一个描述任务的自然语言指令。
0323
1.1 课前准备
T5模型数据集下载并修改代码
tumx和终端不后台从训练
sh Train.sh > ./xxx.log &
tumx
2.1 Scaling Laws
tip:模型规模搞大可以提高自己的能力?
- 实验变量:
C, D, N

- 数据规模与模型规模扩大比:5/8
- 一些超参数的设定
3.1 分布式训练
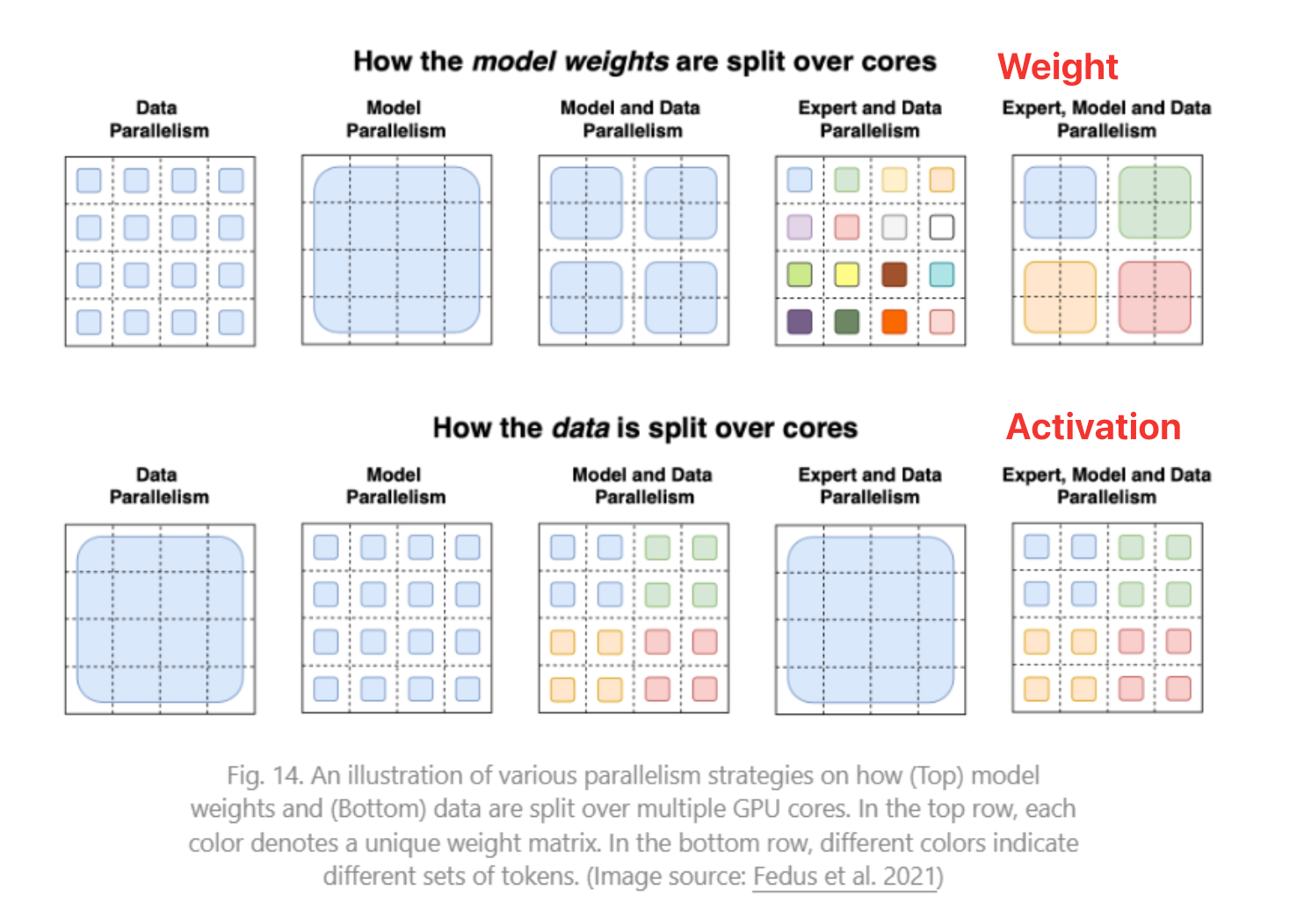
- 并行可以并行哪些?拆哪些?
- 多卡并行范式
数据并行性(DP):将模型(所有weight)复制到别的Worker中,所以模型大于单个显存的时候使用这种方式无法很好工作
模型并行性(MP),存在Bubble问题
MP优化:管线并行性(MP --> PP),又叫流水线并行
pp传播的是activation(前向)和对应的grad(反向)
GPipe的不足:最后一个执行完才能backward
PipeDream:前反向穿插,调度问题很难,工程上=>Pipeline flash。实现one F one B
张量并行性(TP)
前面是纵向分割,现在提出用横向分割
将一个算子的Tenser分到多节点计算
专家混合(EP,MoE)
G shard
switch Transformer
后面还有CP,xxxxP
分布式框架
pytorch的
deepspeed
4. 显存占用问题
4.1 解决方案
之前有多个batch的grad累加
- 重计算(recompute)
Pytorch2.6开始更加新的重计算
offload :用完就放到CPU
eg:
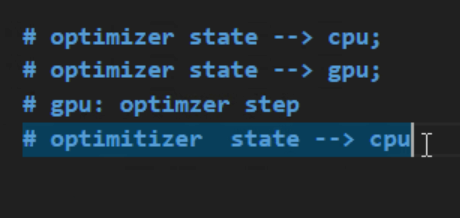
gradient accumulate
4.2 显存分析
1.API
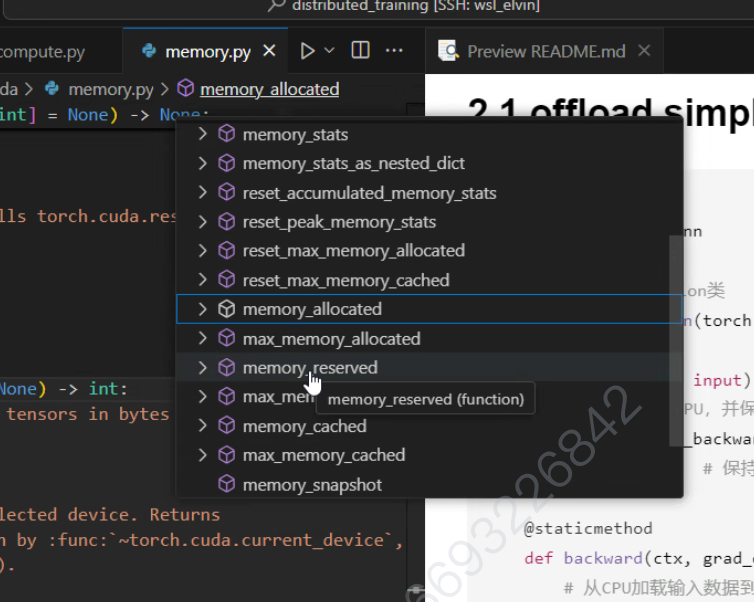
2.显存高峰期
在第一个step不会,理论上是在第二个step的forward之后
5. 混合精度训练(AMP)🌟🌟🌟🌟🌟
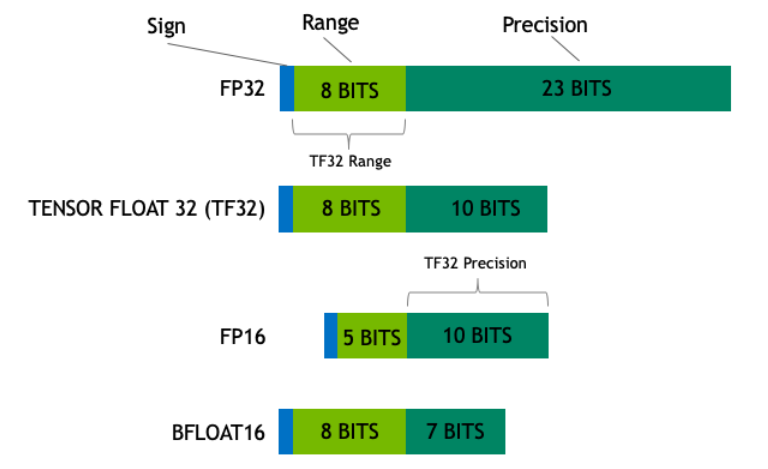
大模型必用,加速训练
==下一个热点FP8==
1.权重副本fp32
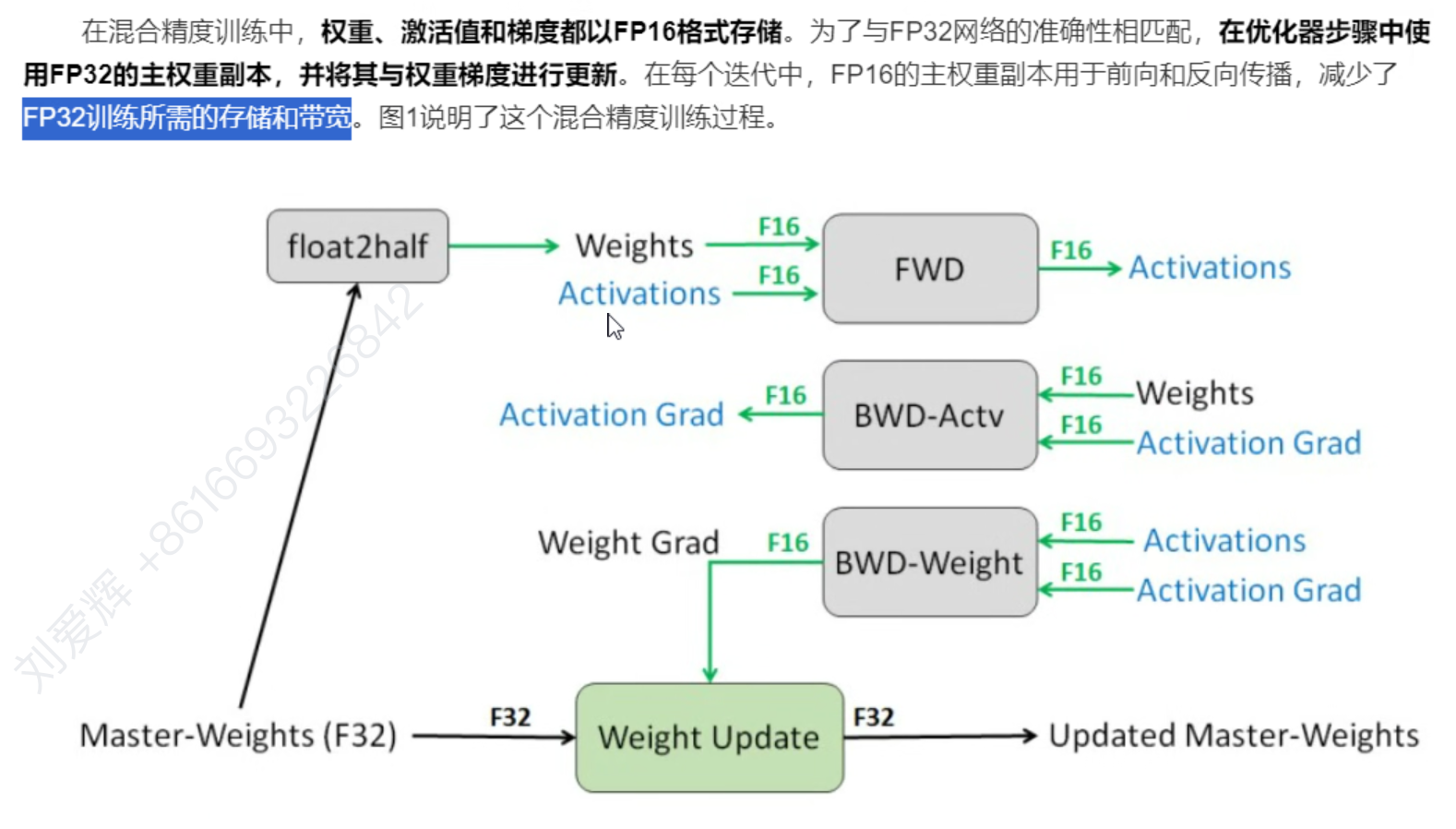
2.损失缩放
3.输出存储到单精度,最终变半精度
舍入误差(下溢)
6. Apex
0329-0330
1. 续分布式训练:
DP
DDP
- Ring All Reduce
- 分桶进行,bucket
- 一个进程单独占用一张卡
- 通信成本是2P(2*param)
nccl通信后端
Gather相当于concat吗,reduce相当于进行了point wise操作吗
是的
B2sixERQSe/b
watch -n
分布式
- 数据采样
- ddp要xxx(忘了)
- init group
2. ==ZeRO策略==系列(分布式训练加速)(原理和案例)
beepspeed框架
ZeRO=>优化内存=》增大batchsize
==属于数据并行的范畴,优化了optim==
显存主要被谁占用?==〉optim的state,而且在混合精度训练时候,在optim的时候是fp32
dp和mp没有解决这一问题
回顾不足
实现了计算和内存双丰收
==将状态states分区==(有三个级别或者三个优化阶段)
分区:optim状态,梯度分区,prarm分区
即:Pos,optim state + g,optim state + g + p
通信量:
分布式这块还需要讲哪些(如果多的话可以先跳过一些困惑)
3. pytorch对zero3的实现——==FSDP==
FSDP有俩个版本,pytorch2.4之前是v1,24后大更新v2,能够很好的进行3d并行
magatore
4. TP张量并行
- 对param切分
- 行并行和列并行
- ==megareoa==
- 上面的方法增大了通信量
- 模型并行
- 列切分和行切分的时候合并再做激活,对MLP的layer1的weight做列切,进行分别激活,(这儿减少了一次通信)然后对layer做行切,最后再做All Reduce
- 与Transformer非常适合结合使用
- 拆头的时候如果切列数不跟head一样数目,会有点点问题(但实际不可能有这种情况)
5. PP
调度策略做得好就厉害
之前的:
setp的batch:group batch
- Gpipe:Micro Batch=> 1. 执行完forward才能backward, 2. pipeline flash(backward执行完才参数更新)
Micro Batch分的越细,bubble越小
- PipeDream:采用异步更新,一个时间步实现forward后会进行backward,即1f2b,(后面会有两种选择,有b先b,没有就f)
有时候weight可能不一样(有些是已经更新后的),但是多保留了一些冗余weight
工程上并没有使用
PipeDream 2BW
==PipeDream Flash==:有明显的一个分界线,来做参数更新
工程使用
- megator对上面这种做了优化:interleaved 1f1b
拆storage的粒度更小
通讯次数变多
近两年:
上面的还是可用的
- zero- bubble
将backward拆成俩(b和w)
一个计算weight的grad,一个计算activation的grad(backward的目的是啥,过程是啥)
pipe flash不再是竖线,而是斜线
- Dual pipe(DeepSeek )
6. SP(sequence P)
TP做完之后对seq做SP
对activation做sp
两个通信g和g‘,
g,这个增加了一点通信量
g'之前是All Reduce,现在使用Reduce- Scatter,而且通信量减少了一点(后面的参数量即显存减少了)
总的通信量与TP的AllReduce一样
7. 3D并行
deepspeed的3D
- 2个大DP(All Reduce),每个DP里面是4组PP实现(跨节点send和resv),每组PP切成4个TP(All Reduce)
8. CP(context P)
==flash Attention==
长文本,会对Activation大量增加,weight只是很少的一部分
EP
EP阶段应当不再有zero策略,Attention需要,MLP做成了EP,除了MLP部分,其他参数的并行是一致的
9. MoE(稀疏MoE)
Gshard
专家(expert)
放在mlp层,也就是mlp
专家主要是区分token,而不是sentence
路由(router)
哪个token发到哪个专家
最后合并根据index,通信用All to All
关键点
1.跟seq大小无关
2.位置关系靠All to All
3.计算参数量会减少,有个分发,所以参数量差不多
存在问题:专家拥堵=> 专家分布不均匀(负载不均衡),某些得不到训练
keep top K策略
token choice
- ==辅助损失==(负载均衡损失)
- 可能会影响模型性能(因为是一种强制平衡性)
- ==辅助损失==(负载均衡损失)
专家容量
1
2
switch transformer
mixtral
DeepSeek MoE
如何把MoE和别的并行结合起来
10. 优化策略总结
11. 监督微调sft
- 指令调优
12. RLHF(强化学习)
==instruct GPT==
PPO(强化学习算法,奖励模型)
工程化落地
13.微调工具
LoRA、PEFT
样本数据+数据加载,
14.推理模型(后训练时代)
Long CoT(长思维链)
15. LLM发展脉络
16. DeepSeek
- V1、v2、v3
- R1 zero、R1:消除了SFT(并没有完全消除),完全采用RLHF(==不使用PPO,采用改进的GRPO==),但是性能有点点慢
- DPO
- PPO
- GRPO
- MLA(前注意)
- MoE
- MTP(多token预测)
- 等等等
- MLA(前注意力)
- YaRN(旋转位置编码)
- 长思维链
==补充:60min==
大模型的工作流通常分为多个模块,每个模块涉及不同的工具和技术栈。以下是 大模型(LLM)开发与部署的完整工作流,并标注了 常见负责模块 和 工具链,方便你明确团队的分工范围。
一、大模型核心工作流
1. 数据准备(Data Preparation)
- 任务:数据收集、清洗、标注、预处理。
- 工具:
- 爬虫/API:Scrapy、BeautifulSoup、Apify。
- 清洗/标注:Pandas、OpenRefine、Prodigy、Label Studio。
- 存储:HDFS、AWS S3、Milvus(向量数据库)。
- 输出:高质量训练数据集(如JSONL、Parquet格式)。
- 负责模块:若团队负责数据工程,需重点优化数据质量。
2. 预训练(Pretraining)
- 任务:在大规模无监督数据上训练基础模型。
- 工具:
- 框架:Megatron-LM(NVIDIA)、DeepSpeed(微软)、ColossalAI。
- 分布式训练:PyTorch + FSDP(全分片数据并行)、NCCL(GPU通信)。
- 硬件:NVIDIA A100/H100集群、TPU Pods。
- 输出:基础模型(如GPT-3架构的Checkpoint)。
- 负责模块:通常由大厂/研究团队完成,中小团队可直接用开源模型(如LLaMA、Falcon)。
3. 微调(Fine-tuning)
- 任务:在领域数据上调整模型。
- 方法:
- 全参数微调:适合数据充足场景。
- 高效微调:LoRA、QLoRA(节省显存)。
- 工具:
- 框架:Hugging Face Transformers、Axolotl。
- 库:PEFT(参数高效微调)、trl(RLHF)。
- 输出:领域适配模型(如医疗、法律垂直模型)。
- 负责模块:若团队专注垂直领域,这是核心模块。
4. 对齐与强化学习(Alignment & RLHF)
- 任务:让模型符合人类偏好。
- 方法:
- RLHF:基于奖励模型(Reward Model)的PPO训练。
- DPO:直接偏好优化(更简单高效)。
- 工具:
- 标注:Scale AI、Amazon Mechanical Turk。
- 训练:trl(Transformer Reinforcement Learning)。
- 输出:对齐后的模型(如ChatGPT风格)。
- 负责模块:若需产品化,对齐是关键。
5. 模型评估(Evaluation)
- 任务:评测模型性能。
- 指标:
- 通用能力:MMLU、Big-Bench。
- 垂直领域:自定义评估集(如代码生成、问答准确率)。
- 工具:
- 评估库:lm-evaluation-harness、HELM。
- 自动化测试:Pytest + CI/CD(GitHub Actions)。
- 输出:模型性能报告。
- 负责模块:所有团队需参与,但可自动化。
6. 推理部署(Inference & Deployment)
- 任务:高效部署模型提供服务。
- 优化技术:
- 量化:GGUF(llama.cpp)、AWQ。
- 推理框架:vLLM、TensorRT-LLM、TGI(Hugging Face)。
- 硬件:NVIDIA T4/A10G(低成本推理)。
- 部署方式:
- API服务:FastAPI + Docker + Kubernetes。
- 边缘设备:ONNX Runtime(移动端)。
- 负责模块:若团队负责落地,这是重点。
7. 应用开发(Application Integration)
- 任务:将模型集成到产品中。
- 场景:
- 聊天机器人:LangChain、LlamaIndex。
- RAG:Elasticsearch + 向量数据库(Weaviate)。
- 工具:
- 后端:Flask/FastAPI。
- 前端:Gradio、Streamlit。
- 负责模块:应用团队核心工作。
二、团队常见分工与工具链
| 模块 | 负责团队 | 核心工具/技术 |
|---|---|---|
| 数据准备 | 数据工程团队 | Pandas、Prodigy、AWS S3 |
| 预训练 | 大模型研究团队 | Megatron-LM、DeepSpeed |
| 微调 | 算法团队 | Hugging Face、PEFT、QLoRA |
| 对齐(RLHF/DPO) | 算法+产品团队 | trl、Scale AI |
| 评估 | 算法+QA团队 | lm-evaluation-harness |
| 推理部署 | 工程/DevOps团队 | vLLM、TensorRT-LLM、Kubernetes |
| 应用开发 | 产品+全栈团队 | LangChain、FastAPI、Gradio |
三、如何选择负责模块?
资源较少团队:
- 聚焦 微调+应用开发(如基于LLaMA做垂直领域模型)。
- 使用开源工具(Hugging Face + vLLM)。
研究型团队:
- 参与 预训练/对齐(需大量算力)。
- 工具:Megatron-LM + DeepSpeed。
工程化团队:
- 主攻 推理优化与部署(如量化、低延迟API)。
- 工具:TensorRT-LLM + Triton Inference Server。
四、典型案例
- ChatGPT类产品:mermaid
graph LR A[数据收集] --> B[预训练] --> C[RLHF对齐] --> D[API部署] --> E[应用集成] - 企业知识库:mermaid
graph LR A[内部数据清洗] --> B[LoRA微调] --> C[RAG系统] --> D[FastAPI服务]
五、关键挑战
- 算力需求:预训练需千卡GPU集群(可考虑云服务如AWS/AutoDL)。
- 数据质量:清洗和标注成本高(可借助合成数据工具)。
- 部署延迟:需优化推理框架(如vLLM的PagedAttention)。
根据团队目标(研究/产品/工程),选择核心模块并匹配工具链。如果需要具体模块的深入方案(如RLHF或量化),可以进一步探讨! 🚀