00-DL_Base_Notes
1. Normalization(还未coding)🌟🌟🌟🌟🌟
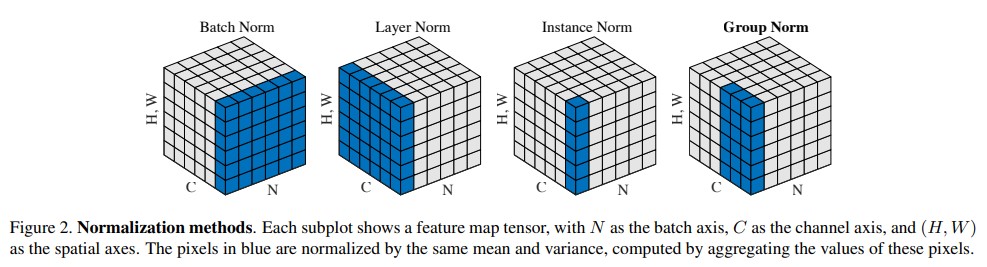
1.1 Norm功能
Batch Norm,Layer Norm,Instance Norm,Group Norm
- 去量纲,把数据调整到更强烈的数据分布
- 减少梯度消失和梯度爆炸
- 主要是有一个计算期望和方差的过程
- 做Norm的粒度不同,应用场景不同
其他资料:Batch Norm的技术博客
1.2 为啥不用BN来做NLP?
- NLP的主要数据格式是[batch_szie, seq_len, embedding_dim]
- Nlp 每个seq都是基本独立的,所以不能用Batch Norm
- LN对应的维度就是对embedding_dim进行的
Batch Norm是逐channel(每个batch的同一个channel)进行标准化,也就是垮batch的。图片恰好需要这种方式。
LN是逐batch进行标准化的。NLP中往往是一个一个的seq进行训练的,而且长度不同,更适合这种。这让我想起了Attention的soft max操作是对一个行向量进行归一化的
LayerNorm有助于稳定训练过程并提高收敛性。它的工作原理是对输入的各个特征进行归一化,确保激活的均值和方差一致。**普遍认为这种归一化有助于缓解与内部协变量偏移相关的问题,使模型能够更有效地学习并降低对初始权重的敏感性。**从架构图上看,LayerNorm在每个Transformer 块中应用两次,一次在自注意力机制之后,一次在FFN层之后,但是在实际工作中不一定如此。
文本长度不确定,而在LN层可以。
1.3 思考
在训练和推理时有何不同???
pytorch的模型有两种模式,在module模块里面有个‘training’属性,也有对应的API,里面明确指出了这个
在BatchNorm采用训练计算的结果(E和Var),应用到测试或者推理的时候
在Dropout后续会说,训练会drop掉,但推理不会,会成(1-rate)
pythondef train(self: T, mode: bool = True) -> T: r"""Set the module in training mode. This has any effect only on certain modules. See documentations of particular modules for details of their behaviors in training/evaluation mode, if they are affected, e.g. :class:`Dropout`, :class:`BatchNorm`, etc. Args: mode (bool): whether to set training mode (``True``) or evaluation mode (``False``). Default: ``True``.对于期望和方差计算策略???
采用移动指数平均,有点类似RNN了
1.4 RMS Norm(大模型使用)🌟🌟🌟
对LN做简化,对于NLP,对缩放敏感,对平移不敏感,所以分子不减,减少了很大计算量

2. Activation🌟🌟🌟
2.1 Non-linear Activations的两种类型
一种是逐元素操作(Element wise 或者Point wise),eg:ReLU,Sigmoid,Tanh,等,另一种是操作对象(元素)之间具有相关性,eg.Softmax
element wise是操作的数据间彼此独立,并且输入与输出大小一致
2.2
3. Loss Function🌟
4. Optimizer🌟🌟🌟🌟
动量后面的Admw那些据估计忘了
5. Transformer🌟🌟🌟🌟🌟
深入理解请阅读Transformer系列文章Transformer
5.1 为啥Attention的时候要除以?
Attention(Q, K, V ) = softmax(\frac{Q·K^T}{\sqrt{d_k}})·V- 个人感觉跟Normalization的作用类似
当 的值比较小的时候,两种点积机制(additive 和 Dot-Product)的性能相差相近,当 dkd**k 比较大时,additive attention 比不带scale 的点积attention性能好。 我们怀疑,对于很大的 dkd**k 值,点积大幅度增长,将softmax函数推向具有极小梯度的区域。 为了抵消这种影响,我们缩小点积 1dk√d**k1 倍。
5.2 为啥拆多头?为啥效果好了?
提取到了更多的信息(类似CNN的multi- kernel),数据分布组与组(子空间)之间独立
Multi-head attention允许模型的不同表示子空间联合关注不同位置的信息。 如果只有一个attention head,它的平均值会削弱这个信息。
减少计算量(应该可以在这一层减少原来的倍)
5.3 Cross Multi-Head Attention?
首先,Self- Attention与传统的Attention机制非常的不同:传统的Attention是基于source端和target端的隐变量(hidden state)计算Attention的,得到的结果是源端(source端)的每个词与目标端(target端)每个词之间的依赖关系。 其次,Self-Attention首先分别在source端和target端进行自身的attention,仅与source input或者target input自身相关的Self -Attention,以捕捉source端或target端自身的词与词之间的依赖关系;然后再把source端的得到的self -Attention加入到target端得到的Attention中,称作为Cross-Attention,以捕捉source端和target端词与词之间的依赖关系。
5.4 Mask Multi-Head Attention
与Encoder的Multi-Head Attention计算原理一样,只是多加了一个mask码。mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
5.5 Masking实现机理
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
5.6 MHA、MQA和GQA
MQA多头共用K,V
GQA将头分组,组内共用KV
5.7 position embedding🌟🌟🌟🌟🌟
attention并不会获取到输入序列(token与token之间)的位置信息,只有俩俩的相关性
最初的Transformer使用的是绝对位置编码,即:直接对第个输入序列的第个token向量加上一个位置编码,然后做同样的attention
关于编码向量(或者矩阵)的生成,采用三角位置编码方式,对于第奇数()个token采用cos,对于偶数采用sin
其中:d表示位置向量的维度(应该也是输入次向量的embedding维度)
其实提取到位置信息是靠变量获取的,相当于是seq index
自己绘图发现该方案存在一定问题: 当embedding dim大于某一范围的的时候,对应编码信息会向0-1分布。我测试的[2, 32, 64],当dim 在[12, 20]发生某种变化,然后超过20开始趋向0-1分布,其实从公式也可以明显发现这种现象
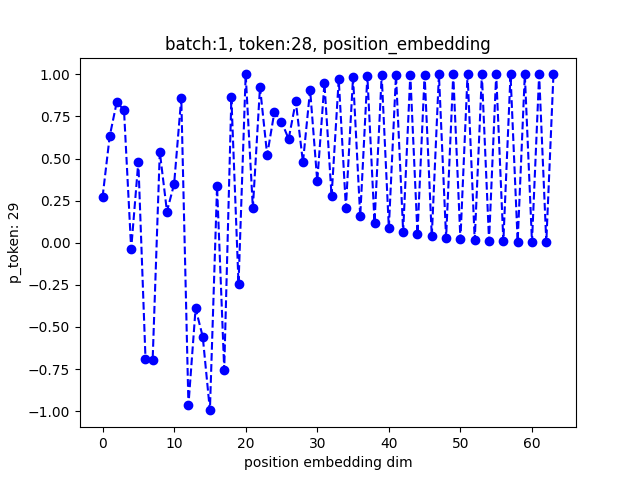
该位置编码是在做Attention之前进行的,与embedding后的向量合并,再做attention
x.x 其他
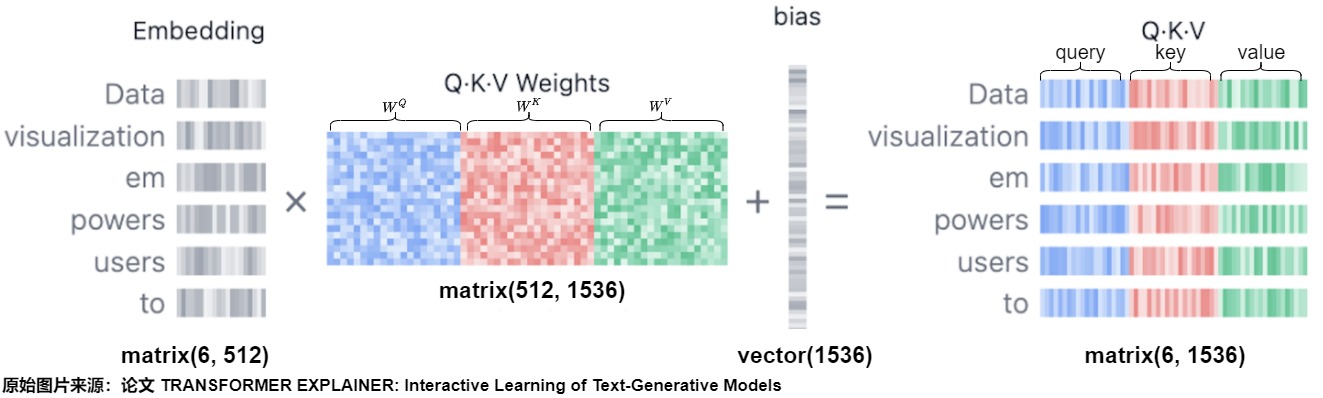
工程中将QKV的权重矩阵直接放在一块,shape就是原来到
Attention的时候是否需要对自身做?自回归的时候应当下一次token尽可能不是上一个词,所以矩阵对角线是否应当是趋于零的?
句子间的相似度计算方式有哪些?Attention为啥采用点积?
addivation
dot-dart (为啥点积运算可以计算相似度)

FFN的时候为啥dim要✖️4放大纬度
encoder其实是特征提取的一个过程
为啥encoder的input和out(context vector)的纬度大小要一样?(因为有原始论文有6个encoder Layer或者cell)
encoder层的attention会注意到前面的词吗?
encoder的特征聚合是在什么时候
特征压缩
softmax的时候是对attention结果的哪个纬度进行归一化(词与词相关性考虑,应该是掩码后矩阵分行向量),为啥归一化?(词与词之间的联系性,因为还要点乘value,所以应当是一个权重)
mask的大小?(batch_size, seq_len, seq_len),应该和attention score一样,因为要码谁就跟谁一样
6. 🌟🌟🌟K-V Cache
7. 🌟🌟🌟常见的正则化方法
- Dropout
8. Bert🌟🌟🌟🌟
输入后的对15%的三个处理
bert有三个编码,分别是
9. 位置编码总结
9.1 绝对位置编码
在Attention之前进行位置编码
对qkv都做位置编码
三角(固定)位置编码
可学习位置编码
把编码矩阵当作可学习参数进行训练(大小与embedding后的输入一致)
Bert模型就是采用的这种编码
9.2 相对位置编码
不使用每个 token 的绝对位置,而是表示 token 之间的相对位置。这样做的好处是,模型不需要对每个位置使用单独的编码,而是通过计算相对距离来捕捉位置信息。
在Attention时候进行位置编码
只对q和k做位置编码,对value不做,value是结果或者说是token本身的特征信息
根据数学原理推导的(依赖之前的位置编码公式来推导,也就是由绝对位置编码启发而来)
采用分桶思想(T5的思想)
9.3 旋转位置编码——RoPE(大模型常用)
也是相对位置编码的一种

通过构建数学模型
根据想要得到的效果进行反推得到
10. 模型的参数和状态
